
少し古いが、本のキャッチによれば統計学は最強の学問だそうだ。なぜならば医学だろうと経済学だろうとビジネスだろうと分野を問わず最も強力な議論の根拠となるのが統計学だからだそうだ。しかし、一介の中小企業のサラリーマンだった筆者には、統計学が最強の学問といわれてもピンとこない。筆者が所属していた部署は営業もしくは事務管理系の部署であるが、そこでの関心ごとである売上の予測や顧客の志向、発注の判断などを過去の推移から判断するということが乱暴すぎるように思えるからだ。
しかし、これは筆者の統計学に対する偏見なのかもしれない。概念では受け入れることができないことも、手を動かすことで理解できることもまましてあるので、手始めにサンプルをもとにR言語を使って重回帰分析をためしてみた。
重回帰分析とは1つの目的変数を複数の説明変数で予測するものだ。
今回は、親の所得と学力(算数平均正答率)の関係を、一人当たり課税額、高学歴人口率、教育扶助受給率という複数の説明変数で予測してみよう。
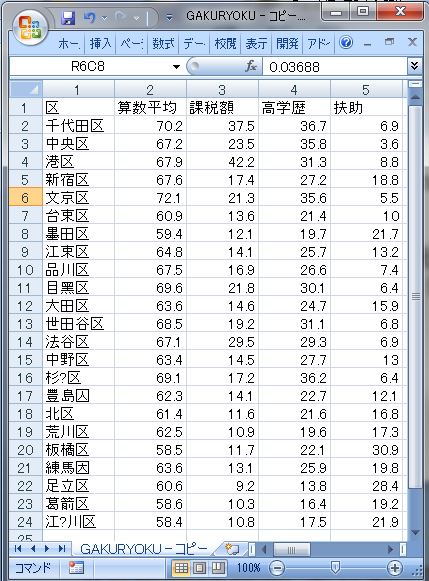
使用するデータは下図のデータだ。

1.データの取り込み
さっそく、R言語用アプリRGUIをhttps://cran.ism.ac.jp/からダウンロードしてインストールする。
R言語用アプリRGUIを起動し、下のようなコマンドを入力してCSVデータを変数gakuryokuにセットする。
gakuryoku <- read.csv(gakuryoku.csv)
2.散布図の作成
まずは散布図の作成。Plot関数を使用する。下のようなコマンドを入力する。
plot(gakuryoku[,-1])
すると下図のような、複数ある目的変数と説明変数の組み合わせごとに散布図がマトリックスの形で表示される。
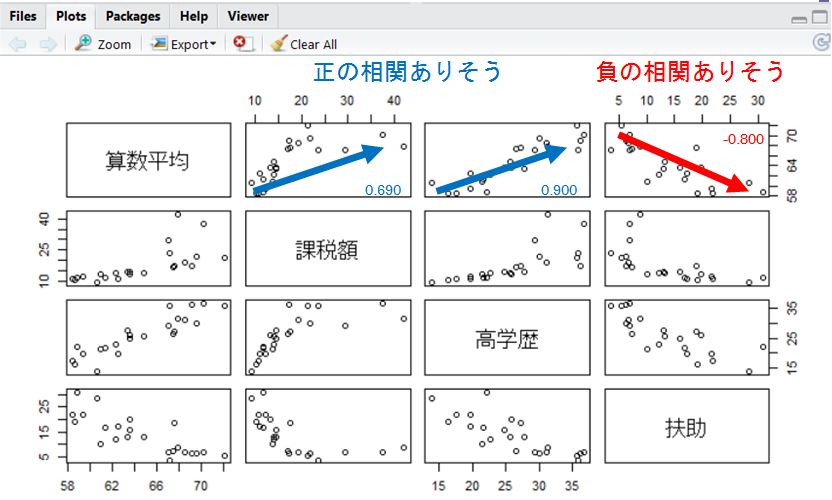
この例では、上図の散布図より算数の平均値は 課税額と高学歴にて正の相関、扶助と負の相関があることが見て取れる。
3.重回帰分析
次に重回帰分析を行う。数式は下記のとおりである。
y=β0+β1×1+β2×2+⋯+βnxn
β1×1+β2×2+⋯+βnxnが説明変数にあたる。
R言語用アプリRGUIでは関数lmを使用する。算出式は目的変数をy 説明変数をXiとして下記のようになる。
lm(y ~ x1 + x2 + x3)
今回の場合は下記のようなコマンドを入力する。
lm.gakuryoku <- lm(gakuryoku[[“算数平均”]]~gakuryoku[[“課税額”]]+gakuryoku[[“高学歴”]]+gakuryoku[[“扶助”]])
この結果はsummary関数を使用することで確認することができる。
今回の場合は下記のようなコマンドを入力すると下図のような結果が返ってくる。
summary(lm.gakuryoku )
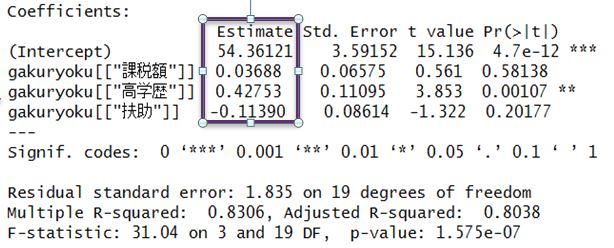
Coefficients の項目の Estimate の列が計算された β の値になる。(Intercept) が β0 であり、x1、x2、x3 の Estimate の値はそれぞれ β1、β2、β3 の値になり、今回求めた重回帰式は下記の通りになる。
y=β0+β1×1+β2×2+⋯+βnxn
理論上の算数平均点=54.36121+0.03688×課税額 + 0.42753×高学歴 - 0.11390×扶助
上述の23区のデータから3つの説明変数から導いた算数平均点と実績値は下記のように導かれる
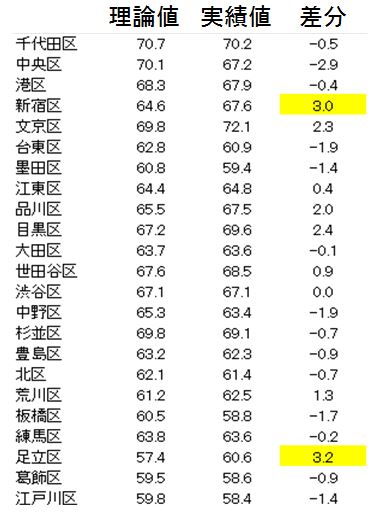
多くの区では理論値と実績値の差分は少なく、親の所得と学力(算数平均正答率)は相関関係にあるということがわかる。
一方、この相関関係に外れた区、黄色でマーカーした重回帰式が導いた理論値と実績値の差分に注目することで、差分が突出した区においては何らかの動きがあったのではないかと仮説を立てることができる。

